


Arm近日在其上海UNLOCK峰会上正式发布面向移动端的全新Arm Lumex计算子系统(Lumex Compute Subsystem,简称Lumex CSS),这套平台以Arm V9.3指令集为基础,涵盖C1系列CPU集群(C1-Ultra、C1-Premium、C1-Pro、C1-Nano)以及新一代Mali G1 GPU家族(Mali G1-Ultra、Mali G1- Premium、Mali G1-Pro)。

Arm Lumex的核心之一是Armv9.3中对矩阵扩展的升级—— SME2(Scalable Matrix Extension 2)。
Arm强调SME2在矩阵与矢量运算方面带来的吞吐量与功耗效率改进,支持对2位与4位量化权重的动态展开与去量化,从而在内存带宽受限的移动端实现更高效的AI推理。

Arm在发布资料中指出,启用SME2的C1系列在多项典型生成式AI、语音识别与计算机视觉等工作负载下,相较上一代能带来多倍的 AI 性能提升与数倍的能效改进。
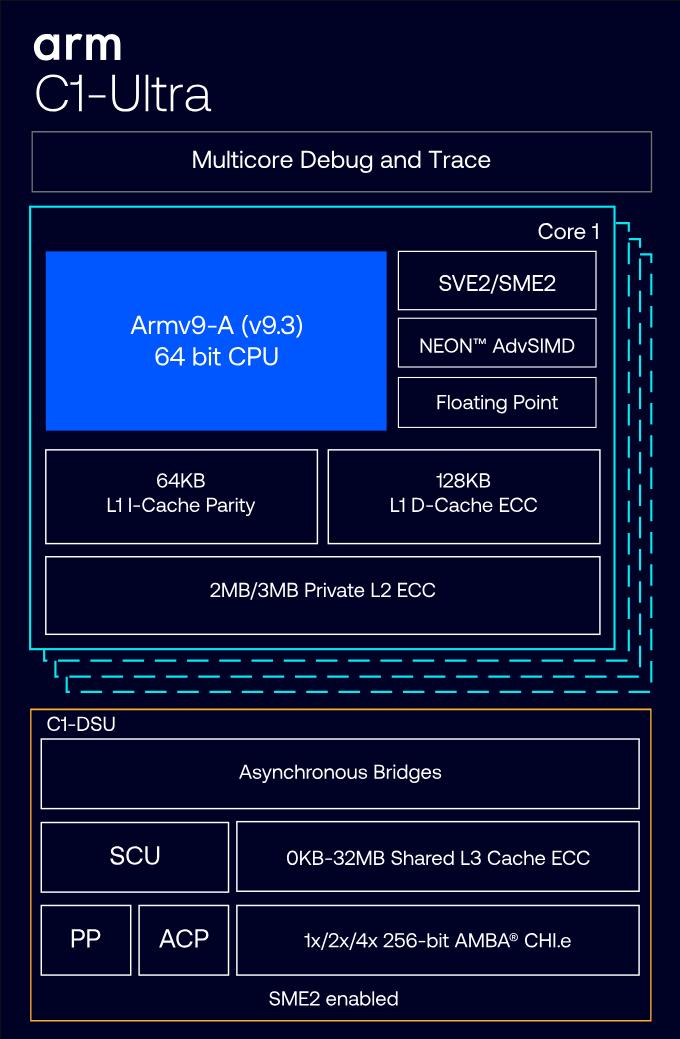
在CPU细分上,C1-Ultra被定位为面向旗舰与高单线程性能的超大核,Arm在发布中给出的目标值包括显著的IPC提升与针对实际工作负载的前端/预取优化;C1-Premium则以“最优PPA(性能/功耗/面积)”为设计目标,适合在面积受限但仍需高性能的次旗舰/高性能产品中取代超大核以获得面积与成本优化;C1-Pro主打高能效大核,C1-Nano则面向可穿戴与超低功耗场景。
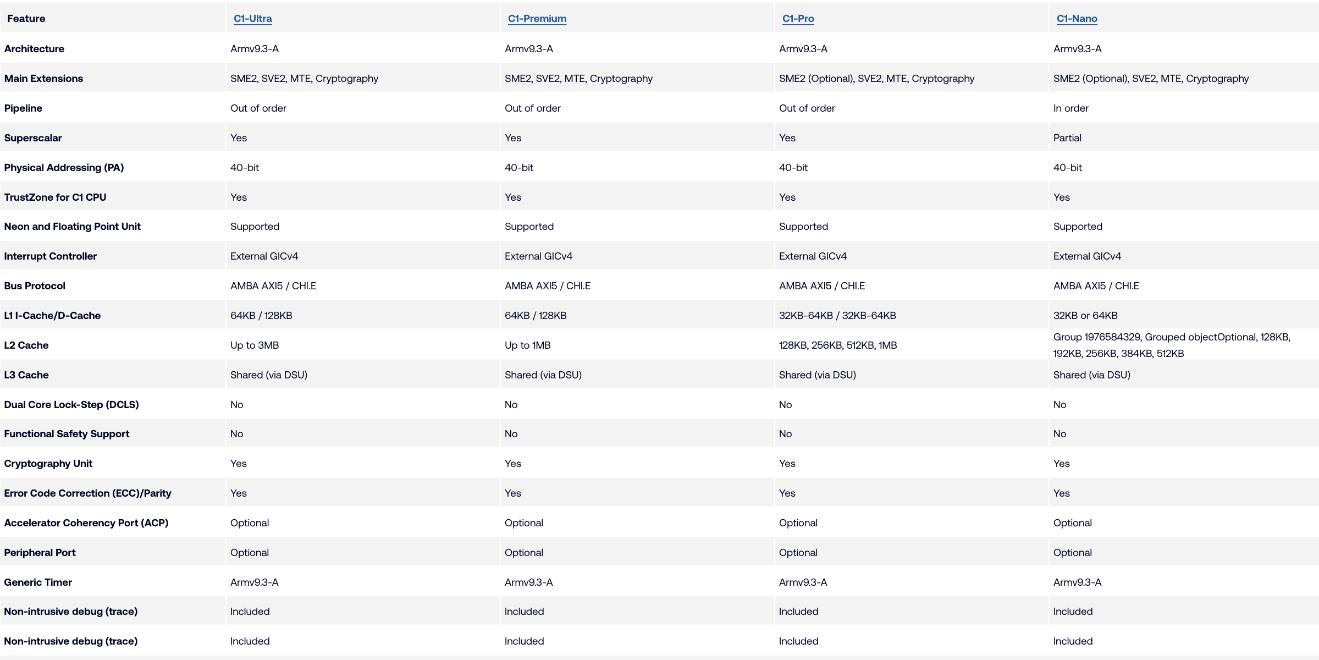
发布会所列的部分基准显示,新一代C1集群在常见移动场景下(游戏、视频、日常应用)平均性能提升与功耗下降的比例。
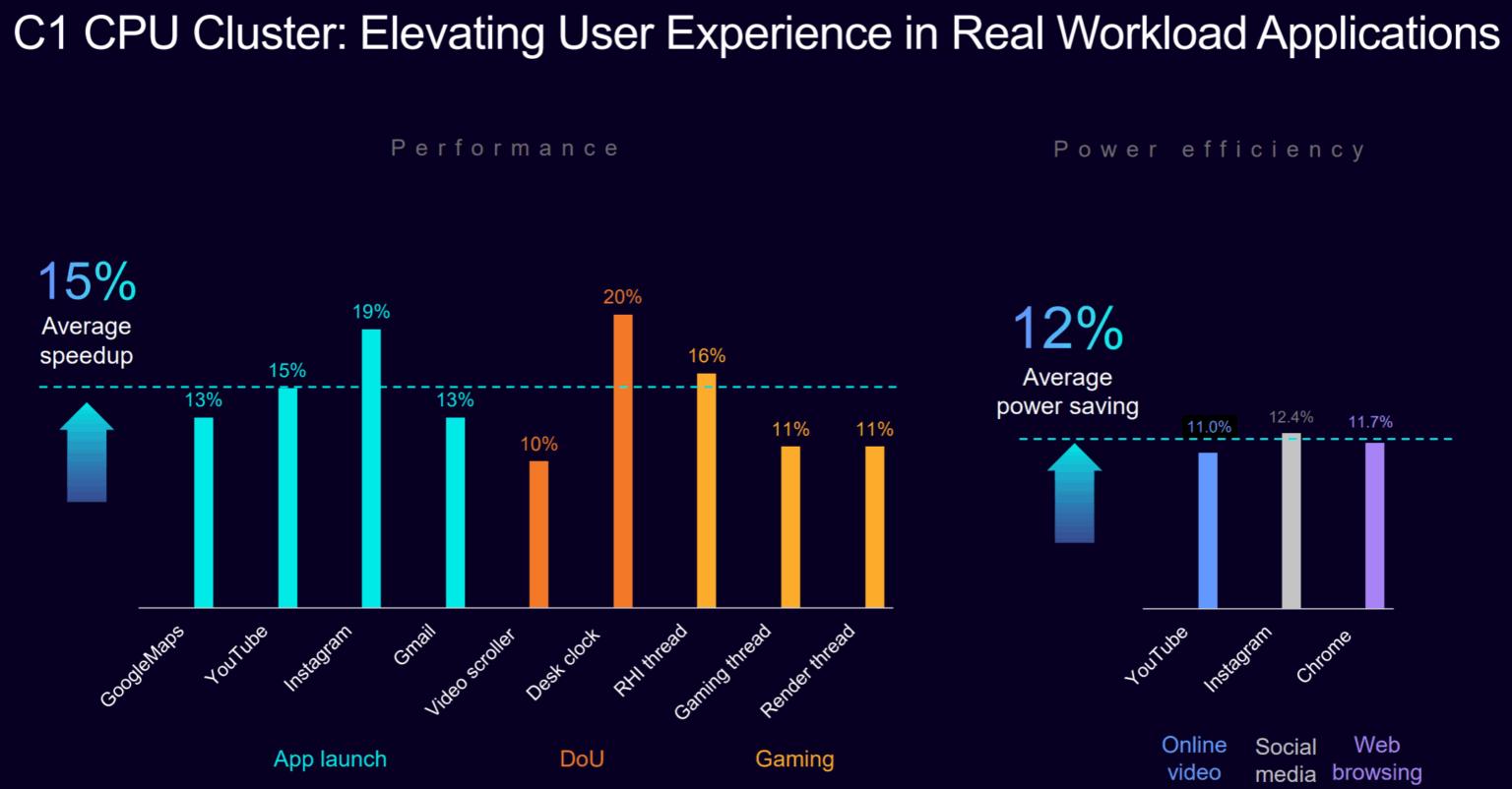
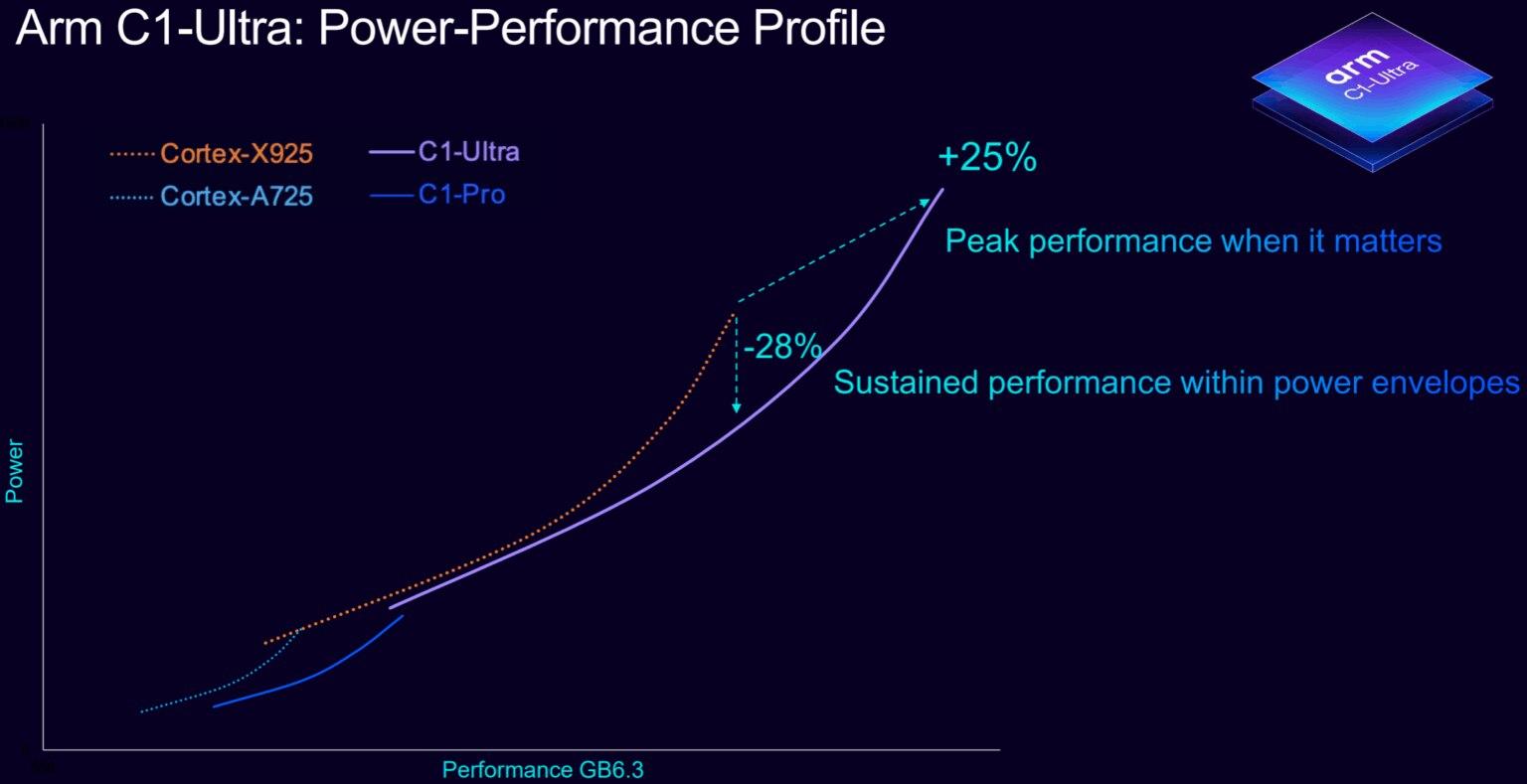
Arm称在若干基准下新平台总体性能相比上一代平均提升约30%,日常应用场景(游戏、流媒体)平均提速约15%,并在同等条件下把功耗降低约12%,而在AI推理方面,启用SME2的C1集群可实现“最多5倍的AI性能提升”与“最高3倍的能效改善”的宣称。
Mali G1系列旨在把“桌面级光追与边缘端 AI”推向手机与轻量终端。
G1通过全新的光线追踪单元(RTUv2)、针对 FP16 的矩阵乘法路径(MMUL/FP16)以及重构的渲染流水线,带来画质与推理双向提升,同时兼顾能效与可扩展性。Mali G1-Ultra的硬件设计核心是为实时光线追踪与 AI 推理分别提供专用加速路径。

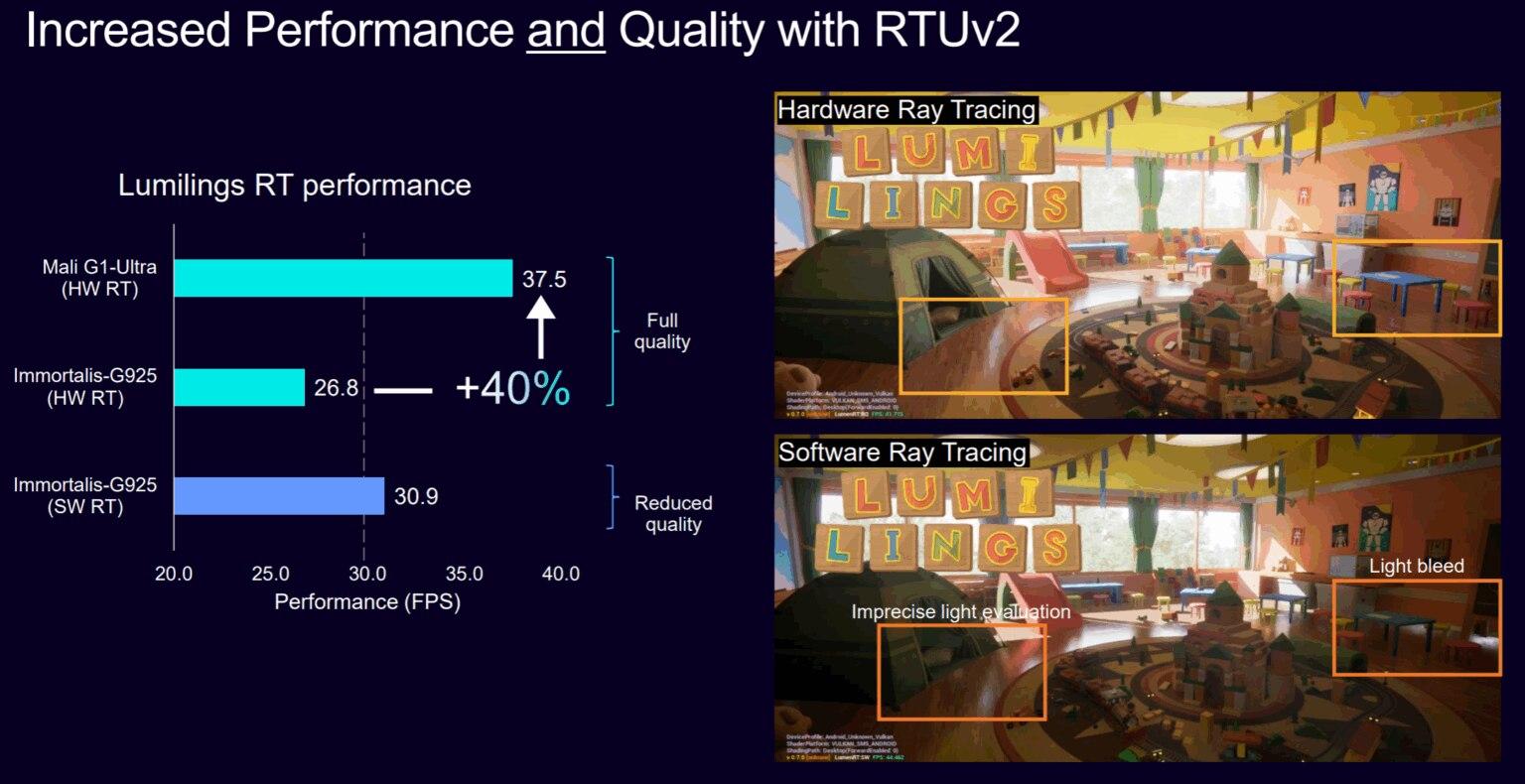
新一代的光线追踪单元 RTUv2 在硬件上支持更高效的 BVH(包围体层次)遍历与光线求解,Arm 宣称相比上一代 Immortalis-G925,RTUv2 在光追性能上可带来最高约 2× 的提升,并在硬件光追游戏中实现更高平均帧率。
RTUv2 的实现思路更偏向“为单光线路径做专门化运算”,从而在移动端的内存与缓存受限场景下获得更稳定的实时表现。
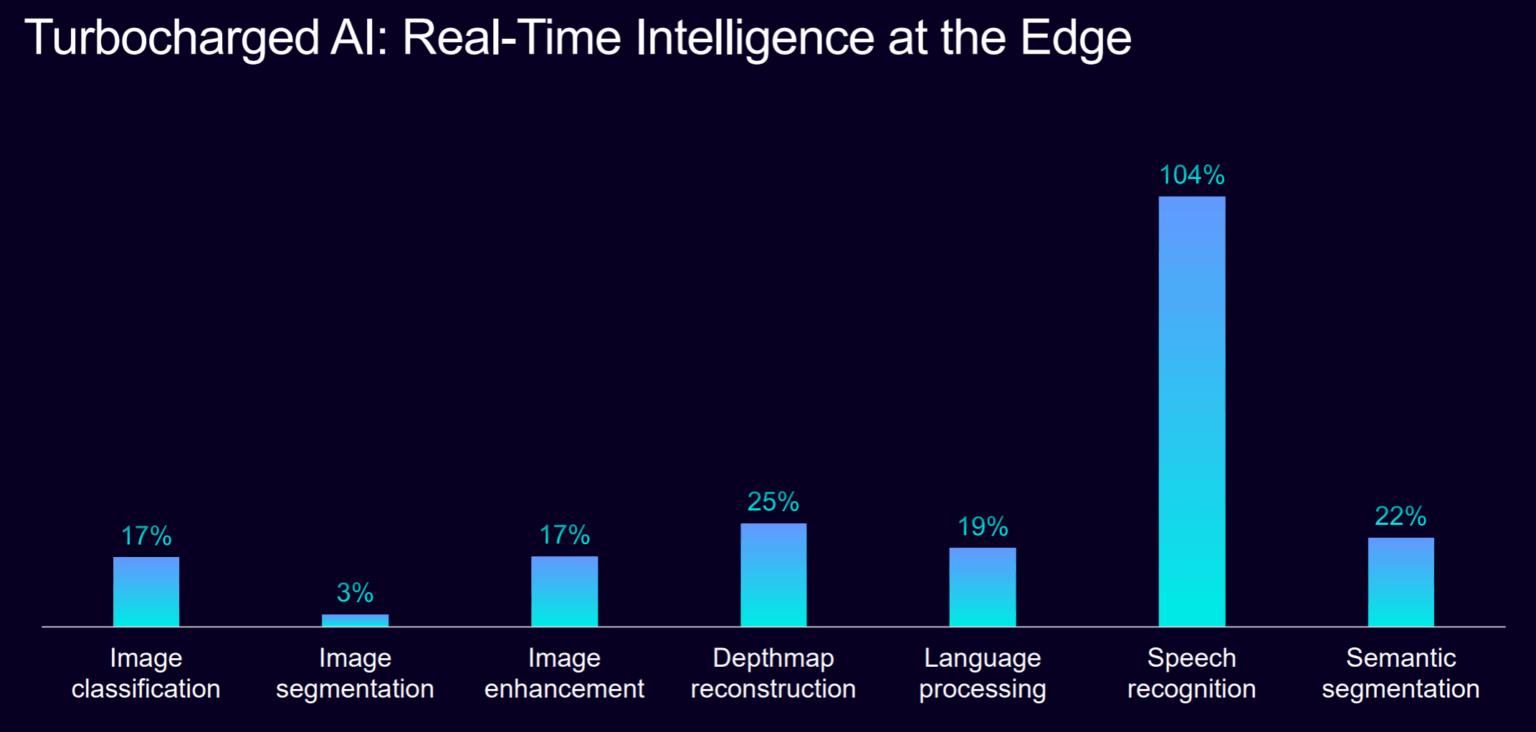
在 AI 能力方面,Mali G1引入了面向FP16的MMUL路径与一系列矩阵计算优化,针对语义分割、图像去噪、深度估计、目标检测与语音识别等常见移动推理任务,Arm 给出的加速幅度显著:在若些网络与工作负载上,GPU 的推理速度较前代可提升约 20%,在特定任务(如某些图像/去噪场景)甚至达到接近或超过 100% 的提升。这意味着厂商在设计 SoC 时,可以将更多 AI 任务交由 GPU 与 RTU 协同处理,减轻对独立 NPU 的全部依赖。
架构可扩展性与系统层优化也是G1的卖点之一。
Arm称 G1-Ultra 可扩展至24 核配置,并在 L2 缓存、互联调度与流水线重构上做出改进,以降低图形与 AI 并发时的内存瓶颈。同时Arm强调了G1在功耗/帧能耗方面的改进:与前代相比每帧能耗可降低约 9%。
富华优配提示:文章来自网络,不代表本站观点。



